不需要让机器真正理解
我们到现在还是计算不出湍流的方程式,但是这并不影响各种飞机依然在天上飞,我们只需要知道这种形状能产生升力就好了。我们不关心过程,只在乎结果。
为自然语言编写规则
20 世纪 50 年代到 70 年代,人们对自然语言处理的认识都局限在人类学习语言的方式上,用了二十多年时间苦苦探寻让计算机理解语言的方法,最终却一无所获。
当时的学术界普遍认为,要让计算机处理自然语言必须先让其理解语言,因此分析语句和获取语义成为首要任务,而这主要依靠语言学家人工总结文法规则来实现。特别是 20 世纪 60 年代,基于乔姆斯基形式语言(Chomsky Formal languages)的编译器技术取得了很大进展,更加鼓舞了研究者通过概括语法规则来处理自然语言的信心。
但是与规范严谨的程序语言不同,自然语言复杂又灵活,许多时候词义还和上下文相关,是一种上下文有关文法(Context-Sensitive Grammars,CSGs),因此仅靠人工编写文法规则根本无法覆盖,而且随着编写的规则数量越来越多、形式越来越复杂,规则与规则之间还可能会存在矛盾。
这一阶段自然语言处理的研究可以说进入了误区。
统计语言模型
直到 20 世纪 70 年代中期,IBM 实验室的贾里尼克(Jelinek)为了研究语音识别问题转换了一下思路,最后用一个简单的统计模型就解决了这个问题。
要判断一句话是不是通顺且正确的(是不是一个人能说出来的),我们需要判断这句话出现的概率,比如一句话S1(我今天吃了火锅)和S2(火锅今天吃了我)我们分别计算P(S1)和P(S2),计算公式为:P(S) = P(w1, w2, …, wn),wn表示句子中的每一个词语。
但这有个问题:我们要计算条件概率:(补公式)
计算会非常复杂,但我们如果只考虑前面的N-1个词呢?也就是:(补公式)
这种假设被称为马尔可夫(Markov)假设,对应的语言模型被称为 N 元(N-gram)模型。
- 但是即使使用3,4元模型,仍然无法覆盖自然语言中的所有情况,通俗来说,这种模型看不了太长的上下文,但自然语言中的上下文跨度可能非常大,所有才有后续的注意力机制
神经语言模型
2003 年,本吉奥(Bengio)提出了神经网络语言模型(Neural Network Language Model,NNLM),使用神经网络来建模文本序列的生成概率。可惜它生不逢时,由于神经网络在当时并不被人们看好,在之后的十年中 NNLM 模型都没有引起很大关注。
直到 2013 年,随着越来越多的研究者使用深度学习模型来处理自然语言,NNLM 模型才被重新发掘,并成为使用神经网络建模语言的经典范例。NNLM 模型的思路与统计语言模型保持一致,通过输入词语前面的 N - 1 个词语来预测当前词。
具体来说,NNLM 模型首先从词表中查询得到前面 N - 1个词语对应的词向量 ,然后将这些词向量拼接后输入到带有激活函数的隐藏层中,通过 SoftMax 函数预测当前词语的概率。特别地,包含所有词向量的词表矩阵也是模型的参数,需要通过学习获得。因此 NNLM 模型不仅能够能够根据上文预测当前词语,同时还能够给出所有词语的词向量(Word Embedding)。
- 到这里就已经有雏形了
Word2Vec 模型
真正将神经语言模型发扬光大的是 2013 年 Google 公司提出的 Word2Vec 模型。Word2Vec 模型提供的词向量在很长一段时间里都是自然语言处理方法的标配,即使是后来出现的 Glove 模型也难掩它的光芒。
Word2Vec 的模型结构和 NNLM 基本一致,只是训练方法有所不同,分为 CBOW (Continuous Bag-of-Words) 和 Skip-gram 两种
其中 CBOW 使用周围的词语来预测当前词,而 Skip-gram 则正好相反,它使用当前词来预测它的周围词语。
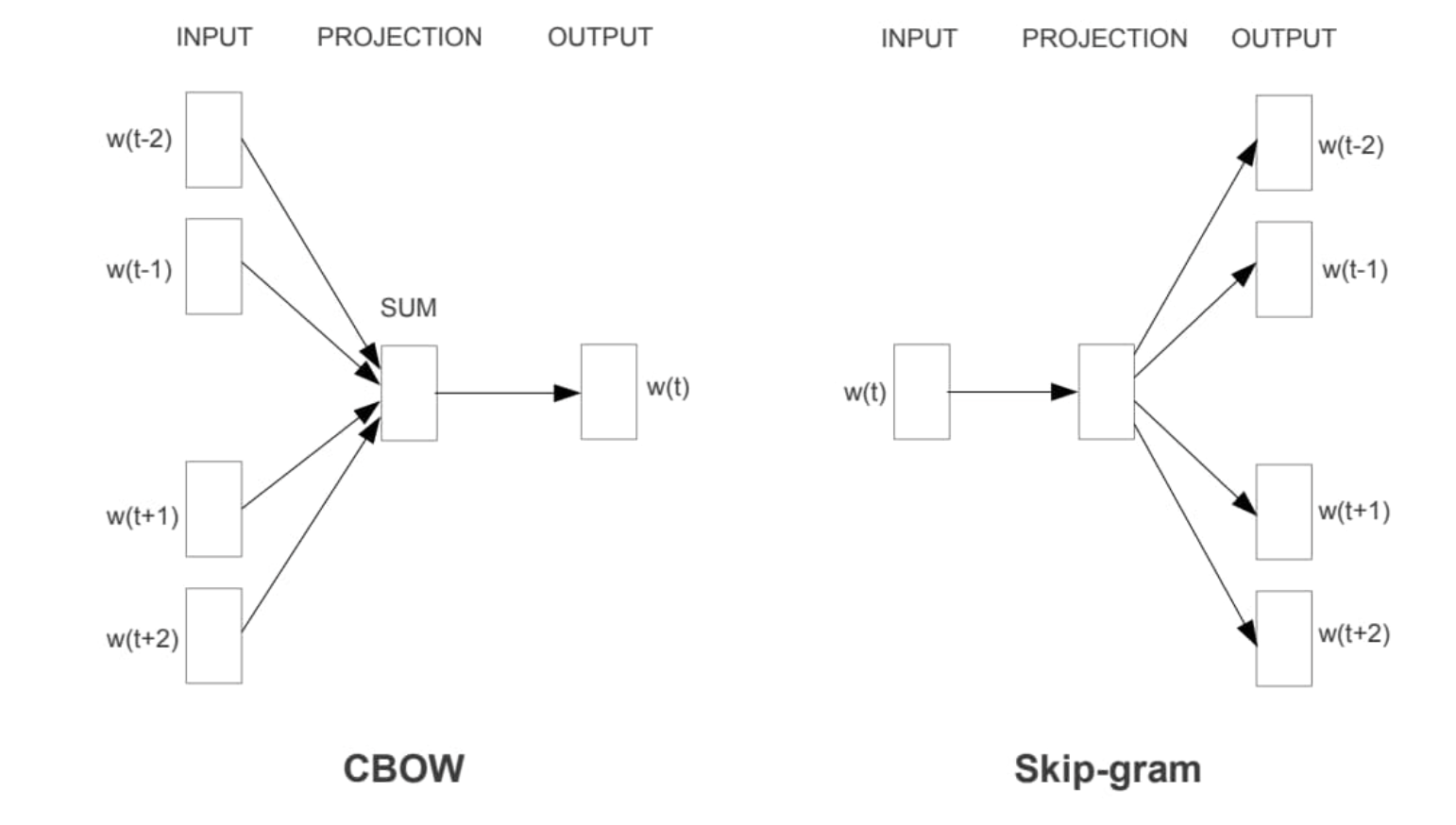
- 但是 Word2Vec 也有弊端,在所有语境下,相同的词只能表示一个向量,比如“苹果”,我”今天吃了一个苹果“,和”苹果公司是一家伟大的公司“两个句子中的苹果是表示的不同的意思,但 Word2Vec 模型会把它们处理成相同的向量
预训练语言模型
在 20 世纪 90 年代初,雅让斯基(Yarowsky)给出了一个简洁有效的解决方案——运用词语之间的互信息(Mutual Information)。
具体来说,对于多义词,可以使用文本中与其同时出现的互信息最大的词语集合来表示不同的语义。例如对于“苹果”,当表示水果时,周围出现的一般就是“超市”、“香蕉”等词语;而表示“苹果公司”时,周围出现的一般就是“手机”、“平板”等词语
因此,在判断多义词究竟表达何种语义时,只需要查看哪个语义对应集合中的词语在上下文中出现的更多就可以了,即通过上下文来判断语义。
ELMo 模型
为了更好地解决多义词问题,2018 年研究者提出了 ELMo 模型(Embeddings from Language Models)。与 Word2Vec 模型只能提供静态词向量不同,ELMo 模型会根据上下文动态地调整词语的词向量。
具体来说,ELMo 模型首先使用大量无标注文本数据对语言模型进行预训练,使得模型掌握编码文本的能力;然后在实际使用时,对于输入文本中的每一个词语,都提取模型各层中对应的词向量拼接起来作为新的词向量。ELMo 模型采用双层双向 LSTM 作为编码器,如图所示,从两个方向编码词语的上下文信息,相当于将编码层直接封装到了语言模型中。
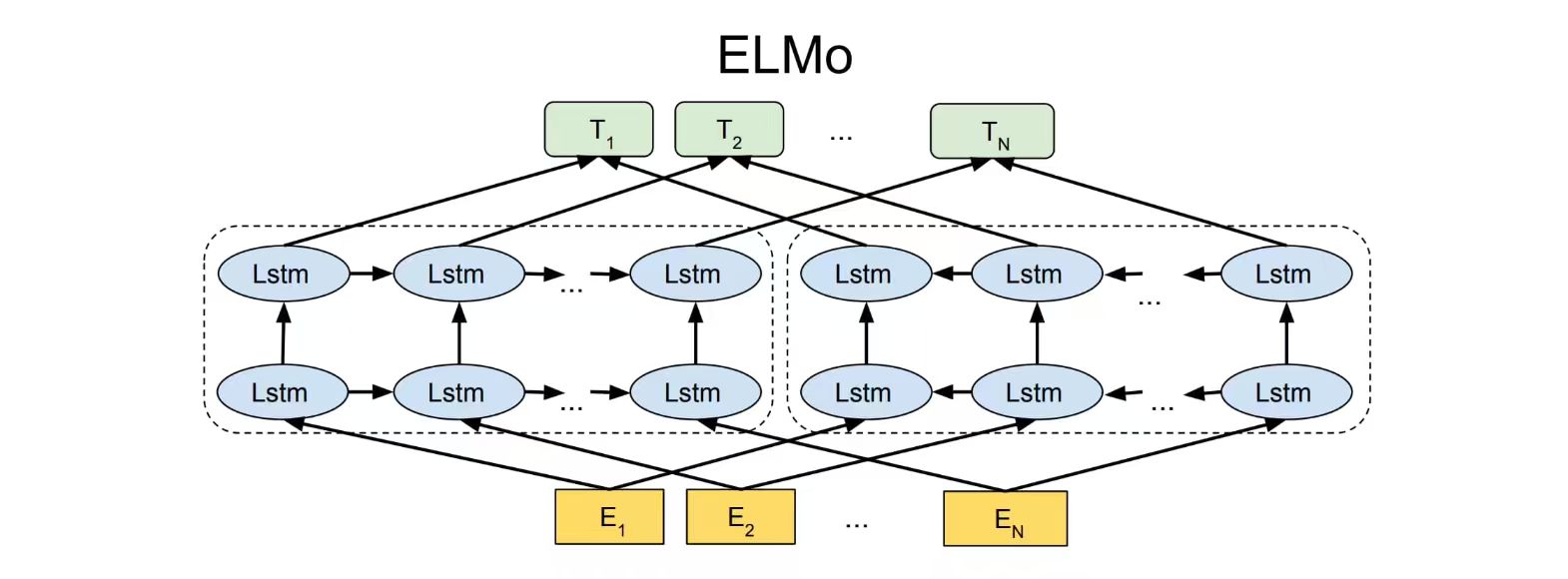
训练完成后 ELMo 模型不仅学习到了词向量,还训练好了一个双层双向的 LSTM 编码器。对于输入文本中的词语,可以从第一层 LSTM 中得到包含句法信息的词向量,从第二层 LSTM 中得到包含语义信息的词向量,最终通过加权求和得到每一个词语最终的词向量。
- 但是 ELMo 模型存在两个缺陷:首先它使用 LSTM 模型作为编码器,而不是当时已经提出的编码能力更强的 Transformer 模型;其次 ELMo 模型直接通过拼接来融合双向抽取特征的做法也略显粗糙。
GPT 模型
不久之后,OpenAI 将 ELMo 模型中的 LSTM 更换为 Transformer 提出了 GPT 模型(Generative Pre-trained Transformer)。并且 GPT 模型继续追随 NNLM 的脚步,采用仅有解码器的 Transformer 架构,只通过词语的上文进行预测。
虽然解码器架构适合于完成自然语言生成任务(如文本摘要),但是在一定程度上也限制了模型的应用场景,例如对于文本分类、阅读理解等任务,如果不把词语的下文信息也嵌入到词向量中就会白白丢掉很多信息。
BERT 模型
2018 年底,Google 基于 Transformer 模型进一步提出了 BERT 模型(Bidirectional Encoder Representations from Transformers),这一阶段神经网络语言模型的发展终于出现了一位集大成者,BERT 模型在发布时在 11 个任务上都取得了最好性能。
BERT 模型采用和 GPT 模型类似的两阶段框架,首先对语言模型进行预训练,然后通过微调来完成下游任务。但是,BERT 不仅像 GPT 模型一样采用 Transformer 作为编码器,而且采用了类似 ELMo 模型的双向语言模型结构,如图所示。因此 BERT 模型不仅编码能力强大,而且对各种下游任务,BERT 模型都可以通过简单地改造输出部分来完成。
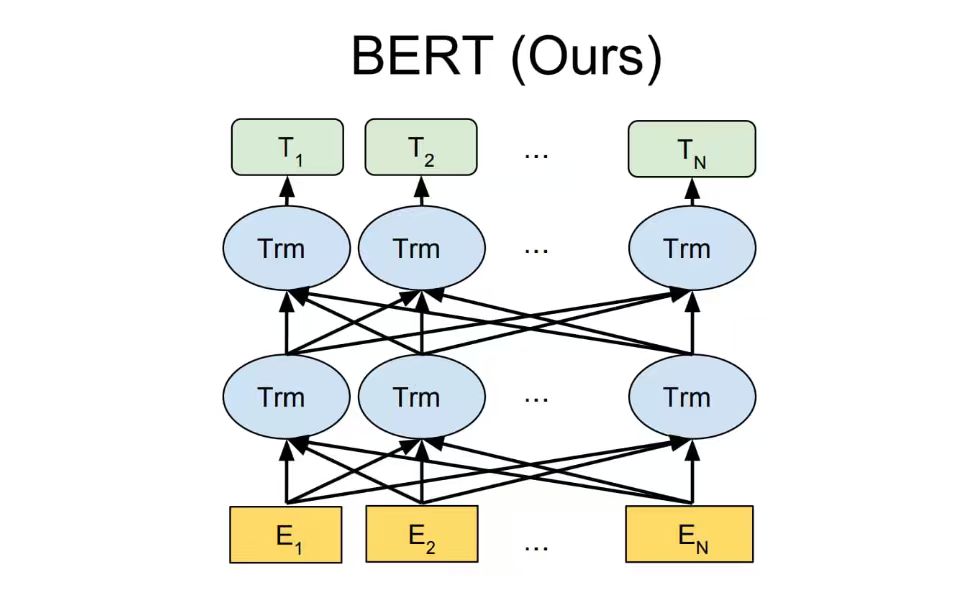
但是 BERT 模型的优点同样也是它的缺陷,由于 BERT 模型采用双向语言模型结构,因而无法直接用于生成文本。后续虽然也有一些“魔改”版本可以用于生成文本,但是编码器架构始终限制着它的生成能力难以超越采用解码器架构的 GPT 模型。
总体来说,以 ELMo、GPT、BERT 为代表的预训练语言模型确立了“预训练—微调”这一工作模式:首先在预训练阶段通过大规模无标注文本建立模型的基础能力,然后在微调阶段使用标注数据对模型进行特定任务适配,进一步提升完成任务的能力。
大语言模型
除了优化模型结构,研究者发现扩大模型规模也可以提高性能。在保持模型结构以及预训练任务基本不变的情况下,仅仅通过扩大模型规模就可以显著增强模型能力,尤其当规模达到一定程度时,模型甚至展现出了能够解决未见过复杂问题的涌现(Emergent Abilities)能力。例如 175B 规模的 GPT-3 模型只需要在输入中给出几个示例,就能通过上下文学习(In-context Learning)完成各种小样本(Few-Shot)任务,而这是 1.5B 规模的 GPT-2 模型无法做到的。为了区分这两代模型之间的差异,业界将大型预训练语言模型命名为“大语言模型”(Large Language Model,LLM)。
大语言模型也存在一些重要的局限性:
- 幻觉:大语言模型可能会生成错误信息。
- 缺乏真正理解:大语言模型缺乏对世界的真正理解,本质上只是依据统计模式工作。
- 偏差:大语言模型可能会重现训练数据或输入中存在的偏差。
- 上下文窗口:大语言模型的上下文窗口数量有限(不过这种情况正在改善)。
- 计算资源:大语言模型需要大量的计算资源。
此外,对于理解歧义、文化背景、讽刺和幽默等更为困难的语义理解任务,尽管大语言模型在多样化数据集上进行了大规模训练,但在许多复杂场景中其理解能力仍然无法达到人类水平。
小结
可以看到,自然语言处理技术的发展并非一帆风顺,期间也曾走入歧路而停滞不前。正是一代又一代研究者的不懈努力才使得该领域持续向前发展并取得了许多令人印象深刻的成果。如今预训练语言模型、大语言模型在学术界和工业界都获得了广泛的应用,深刻地改变着我们的生活,这些成功并非一蹴而就,而是“站在巨人的肩膀上”
之后的故事我们都很熟悉了,2020年GPT3横空出世,后来国内外许多大模型井喷式爆发,后来提示词工程,上下文工程,还有最近的驾驭工程不断发展,agent出现,mcp,skill给模型装上了手脚……