改进Boost-searcher搜索引擎项目
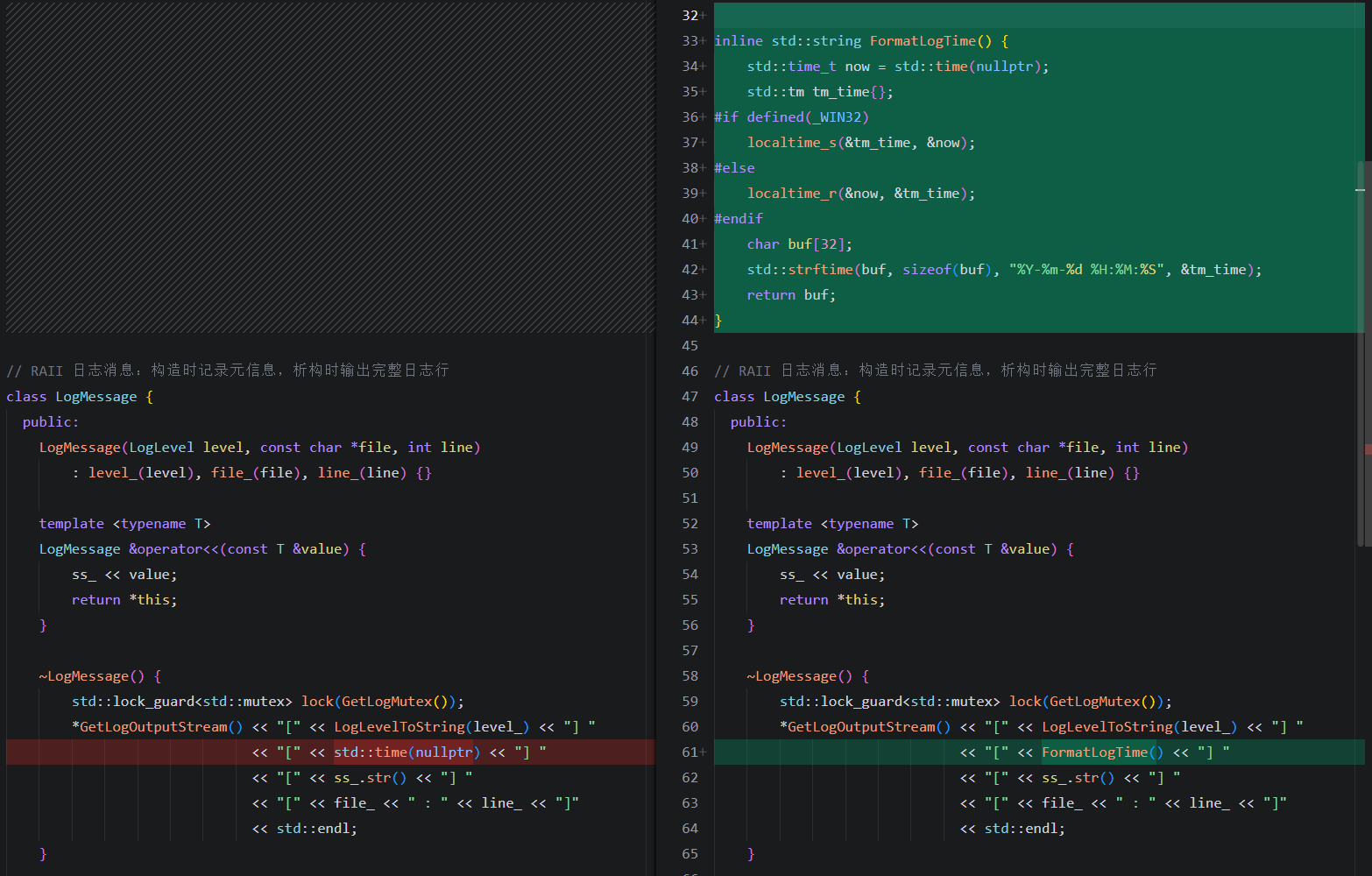
改进日志时间格式为可读的日期时间格式
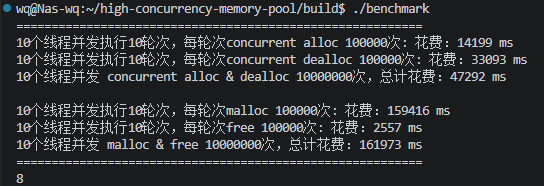
添加高并发负载benchmark测试
为项目添加查询缓存,减少重复计算
使用
partial_sort优化top-K结果排序,提升大规模数据集性能在
Makefile中添加-O3优化标志提升编译后性能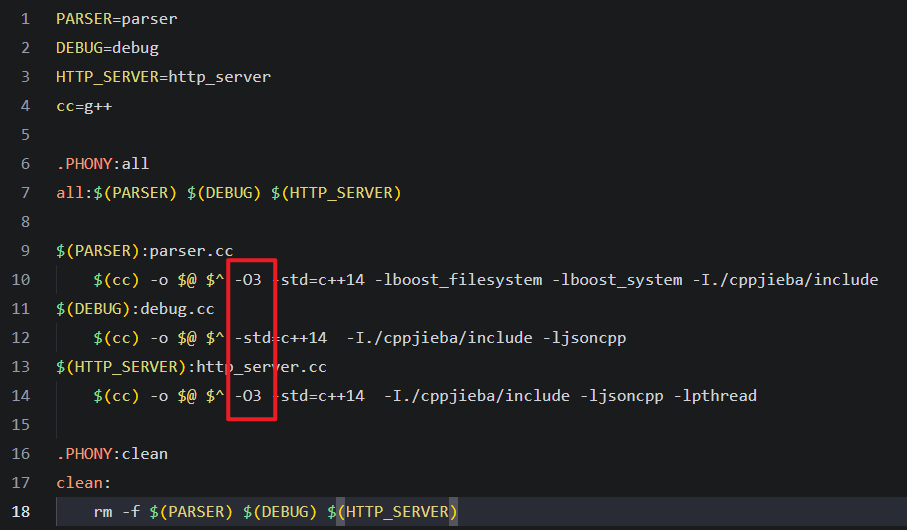
新增性能测试脚本
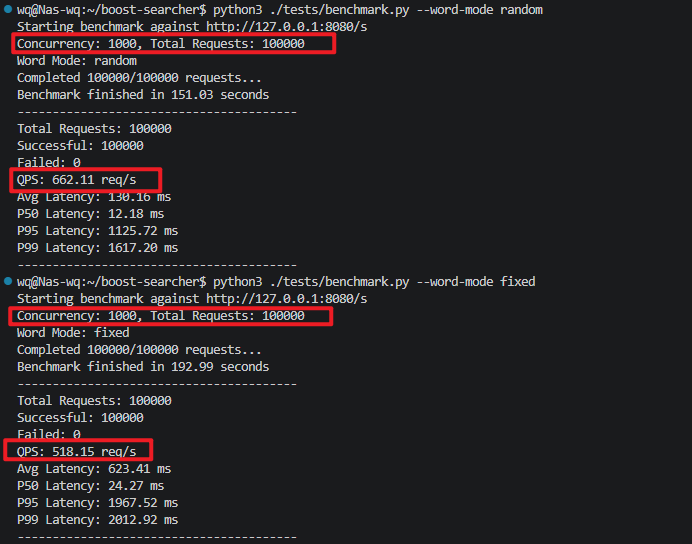
1000个用户,一共发起十万请求,和1000个用户发起一百万请求,数据如上
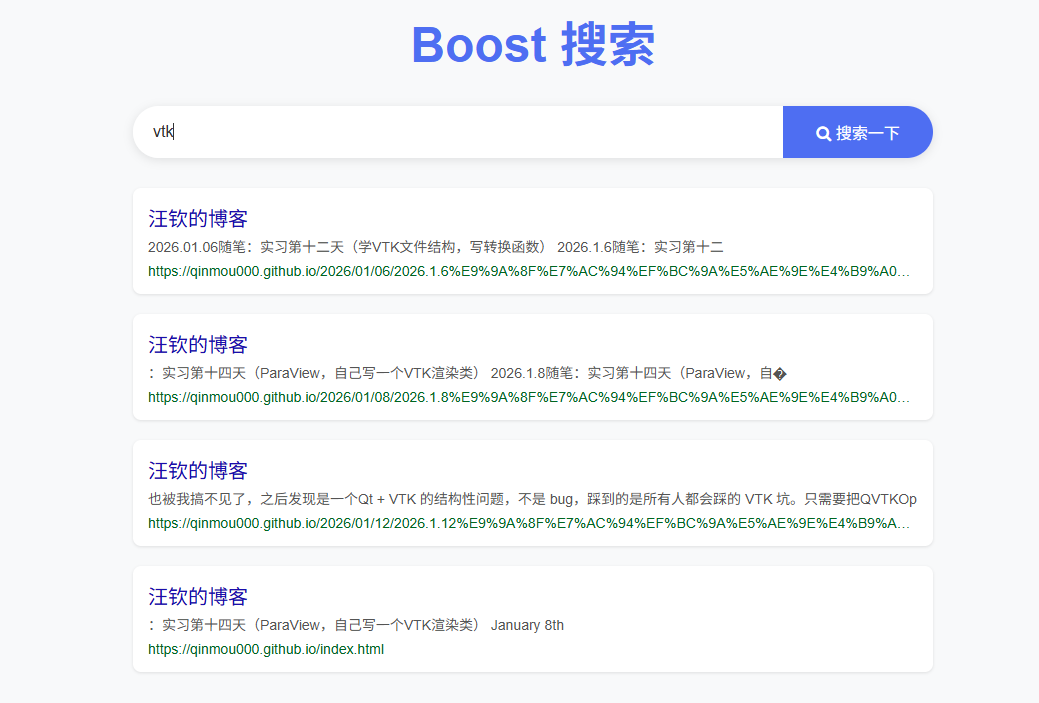
将搜索范围从boost库官方界面,调整至个人博客
python脚本爬取博客html页面,保存本地- 修改
parser模块,添加命令行参数 支持解析任意目录下的html输出到任意目录 并设置任意baseURL
还有哪些可以优化的点?
1. 搜索算法与质量(核心)
这是搜索引擎的灵魂,目前的实现比较朴素。
- 引入相关性评分算法 (BM25/TF-IDF) :
- 现状 :目前是简单累加词频权重。
- 优化 :实现 TF-IDF 或 BM25 算法。不仅看词出现的次数,还要看词的稀有程度(比如“的”、“是”这种高频词权重应该很低,而“Linux”这种稀有词权重高)。
- 停用词过滤 (Stop Words Removal) :
- 现状 :分词后所有词都进索引。
- 优化 :建立一个停用词表(如 the , a , is , 了 , 的 ),构建索引时直接丢弃这些无意义的高频词,能显著减小倒排索引体积并提升搜索速度。
- 同义词与拼写纠错 :
- 优化 :用户搜 “socket” 时,也能召回 “tcp/ip” 或 “network” 相关文档;用户输错成 “serach” 时自动纠正为 “search”。
2. 索引存储与性能(架构)
- 索引持久化与快速加载 :
- 现状 :每次启动都要读取 raw.txt 重新分词、构建索引,启动慢。
- 优化 :将构建好的内存索引(倒排+正排) 序列化 保存到磁盘二进制文件。启动时直接 mmap 或反序列化加载,实现 秒级启动 。
- 正排索引冷热分离 :
- 现状 :所有文档的标题和 正文 都存在内存里 ( vector
),非常耗内存。 - 优化 :内存中只存倒排索引和简单的文档元数据(ID、标题、磁盘偏移量)。 正文内容保留在磁盘上 ,只有在生成搜索结果摘要时,才根据偏移量去磁盘读取(SSD 随机读很快)。这将大幅降低内存占用,单机可支撑百万级文档。
- 现状 :所有文档的标题和 正文 都存在内存里 ( vector
- 倒排索引压缩 :
- 优化 :使用 Varint 、 Delta Encoding (差分编码) 或 PForDelta 算法压缩倒排链表,减少内存带宽消耗。
3. 并发模型与网络
- 异步非阻塞 I/O :
- 现状 : httplib 是同步阻塞模型,依赖线程池堆积连接。
- 优化 :引入 epoll 或使用异步框架(如 Workflow , brpc , drogon ),实现单线程处理成千上万个并发连接,彻底解决 C10K 问题。
- 分页机制 :
- 现状 :一次性返回 Top 100 结果,传输量大且前端渲染慢。
- 优化 :后端支持 offset 和 limit 参数,前端实现分页浏览。
4. 前端体验
- 关键词高亮 (Highlighting) :
- 现状 :后端截取了摘要,但没有给关键词加粗/标红。
- 优化 :前端拿到结果后,利用 JS 正则匹配关键词并包裹 标签。
- 搜索建议 (Auto-complete) :
- 优化 :输入框支持输入前缀时,通过 Trie 树 (字典树)快速返回热门补全词。
5. 运维与监控
- 配置化管理 :引入 yaml 或 json 配置文件,管理端口、日志级别、数据路径等,而不是写死或仅靠命令行。
- 监控埋点 :接入 Prometheus,实时监控 QPS 、 P99 延迟 、 索引内存占用 等关键指标。
改进高并发内存池项目
修复,非必现段错误
修正Common.h中PAGE_SHIFT定义,Windows为13(8KB),Linux为12(4KB)
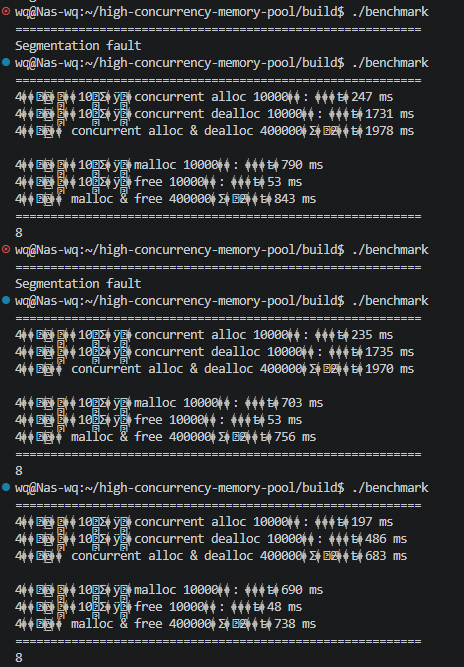
更新SysAlloc和SysFree函数以支持Linux的mmap和munmap系统调用
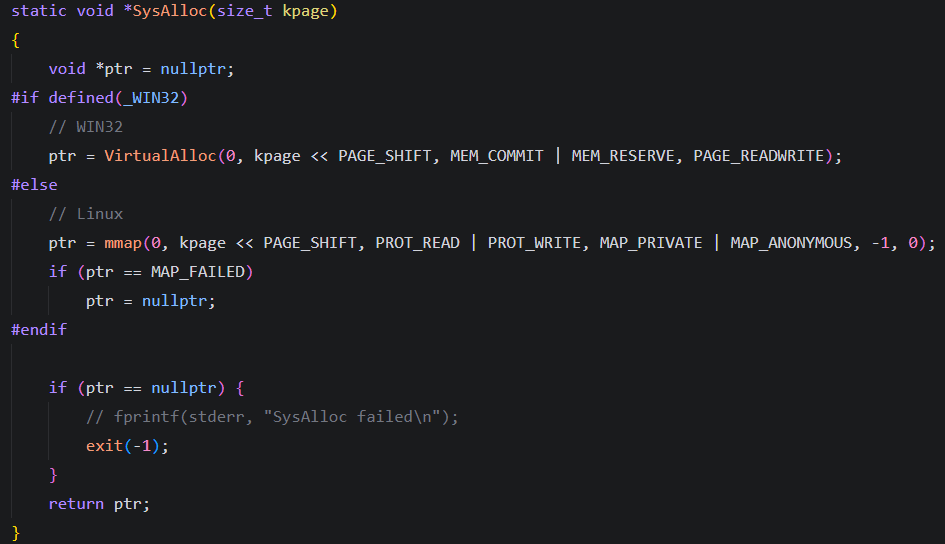
修复PageCache中释放大span时SysFree缺少页数参数的问题
调整CentralCache内存块切分逻辑,防止越界和死循环
更新CMakeLists.txt中字符集设置,区分Windows和Linux平台
添加Linux头文件支持并修正PAGE_ID类型定义
优化结果
还有哪些可以优化的点?
高优先级
- 修复
ListTooLong单节点不回收问题:当start == end时当前代码不会把这 1 个对象回收到 CentralCache,长期会导致对象滞留在线程本地链表。ThreadCache.cpp:L64-L74 - 统一 RAII 锁管理:目前大量手动
lock()/unlock(),异常路径或早返回时有风险,建议改std::lock_guard/std::unique_lock。ConcurrentAlloc.h:L21-L24、CentralCache.cpp:L19-L25、CentralCache.cpp:L75-L110 - 去掉
SpanList::Erase的“静默 return”:现在如果_next/_prev为nullptr会直接 return,容易掩盖链表损坏,建议改成断言失败并尽早暴露 bug。Common.h:L335-L357
性能优化(收益会很明显)
- 降低
MapObjectToSpan锁竞争:ReleaseListToSpans每释放一个对象都调用一次MapObjectToSpan,每次都抢_pageMutex,这是 dealloc 慢的核心来源之一。CentralCache.cpp:L119-L123、PageCache.cpp:L75-L89 - 清理
FreeList::pushRange调试遍历:目前每次pushRange都线性遍历链表计数,属于纯调试开销,压测下很伤吞吐。Common.h:L115-L135 - 减少 benchmark 干扰项:
v.shrink_to_fit()每轮都做会引入大量额外分配释放,建议只clear();统计也建议用线程局部累加后汇总,减少原子热写。Benchmark.cpp:L47-L53、Benchmark.cpp:L115-L121
可维护性 / 工程化
- 把关键参数改可配置:如
MAX_BYTES/NPAGES、benchmark 线程数和轮次,避免写死在源码里。Common.h:L23-L26、Benchmark.cpp:L148-L154 - 补 Sanitizer 构建选项:建议在 CMake 增加可选
ASan/TSan开关,后续排查竞态和越界会更高效。CMakeLists.txt - 处理 TLS
ThreadCache生命周期:当前是new ThreadCache后不回收,虽不致命但会被 LeakSanitizer 报告;可改thread_local智能对象或线程退出回调清理。ConcurrentAlloc.h:L32-L38
如果你愿意,我可以下一步直接按“先稳后快”给你出一个最小改动 patch(先修 ListTooLong + 去调试遍历 + RAII 上锁)。
关于_pageMutex的锁竞争导致的性能下降
_pageMutex 是 PageCache 的全局互斥锁,作用是保护页级共享数据结构在多线程下不被并发破坏。
位置在 PageCache.h。
它主要保护两类共享状态:
_spanLists(各页数桶链表)_idSpanMap(页号到Span*的映射)
代码里典型加锁点:
- 在对象释放时查归属 span:
MapObjectToSpan内部加锁 PageCache.cpp:L75-L89 CentralCache向PageCache申请/归还 span 时显式加锁 CentralCache.cpp:L20-L25、CentralCache.cpp:L140-L143- 大对象直接分配/回收也会经过它 ConcurrentAlloc.h:L21-L24、ConcurrentAlloc.h:L51-L53
一句话理解:
谁要动 PageCache 的“页桶和页号映射”,谁就得先拿 _pageMutex。
代价是它会成为高并发下的热点锁(尤其在 dealloc 路径)。