
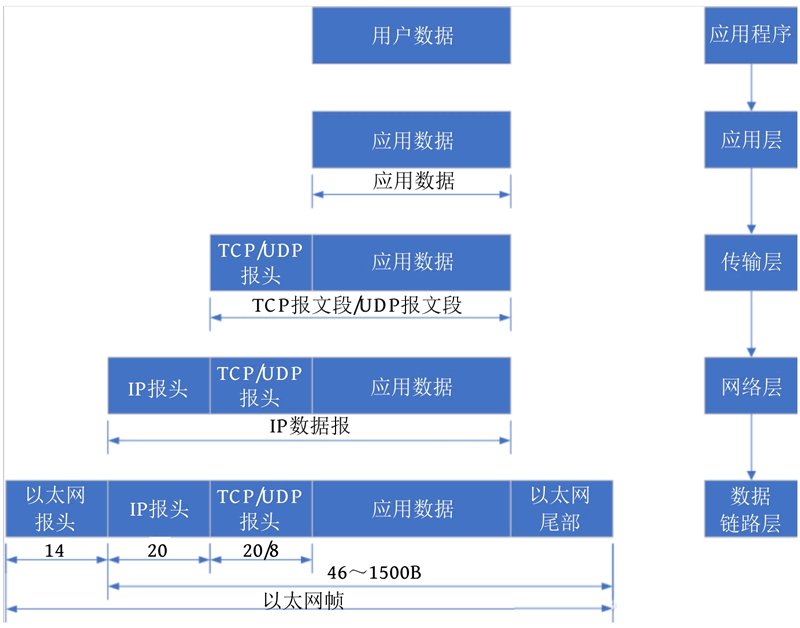
网络:网络层(IP协议)和数据链路层❤
网络层中的IP协议目的就是,在整个网络世界中找到目标主机
网络层
IP协议报头格式:

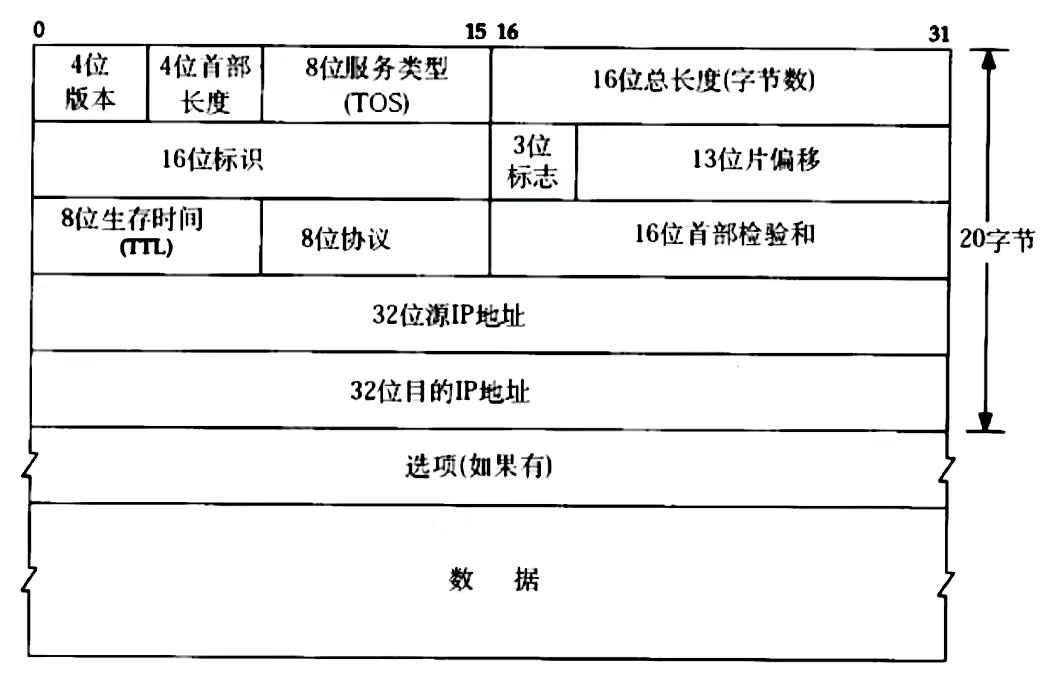
- 4位版本号
version:指定IP协议的版本号,IPv4版本号就是4 - 4位头部长度
header length:IP头部长度有多少个32bit,4bit表示的最大的数组是15,所以IP头部长度最大就是60字节 - 8位服务类型
Type Of Service:三位优先权字段(弃用),4位TOS字段,和1位保留字段(必须置零);四位TOS字段分别表示:最小延时,最大吞吐量,最高可靠性,最小成本。这四者相互冲突,只能选择一个,对于ssh、telnet这样的程序,最小延时比较重要;对于ftp,最大吞吐量比较重要 - 16位总长度
total length:IP数据包整体占多少个字节 - 16位标识
id:唯一标识主机发送的报文,如果IP报文在数据链路层被分片了,每一个分片的id都是一样的 - 3位标志字段:第一位保留;第二位置1表示禁止分片,这时候如果报文长度超过MTU👇,IP模块就会直接丢弃报文;第三位表示是否还有更多分片,如果分片了的话,最后一个分片此标记位置为0,其他是1,类似一个结束标记
- 13位分片偏移
framegament offset:是分片相对与原始报文开始处的偏移,其实就是表示当前分片在原始报文中的位置,实际偏移的字节数是这个值*8得到的,所以,除了最后一个报文之外,其他报文的长度必须是8的整数倍 - 8位生存时间
Time To live (TTL):数据包到达目的地的最大报文跳数,一般就是64,每经过一个路由 TTL -= 1,一直减到0还没到达,那么就丢弃了,这个是为了防止循环路由 - 8位协议:表示上层协议的类型
- 16位头部校验和:使用CRC校验,鉴别头部是否损坏
- 32位源地址和32位目标地址:表示发送端和接收端
- 选项字段:不定长,最多40字节
网段划分
IP地址分为两个部分:
网络号:表示互相连接的两个网段的不同标识
主机号:同一网段内,主机之间具有相同的网络号,但主机号不同
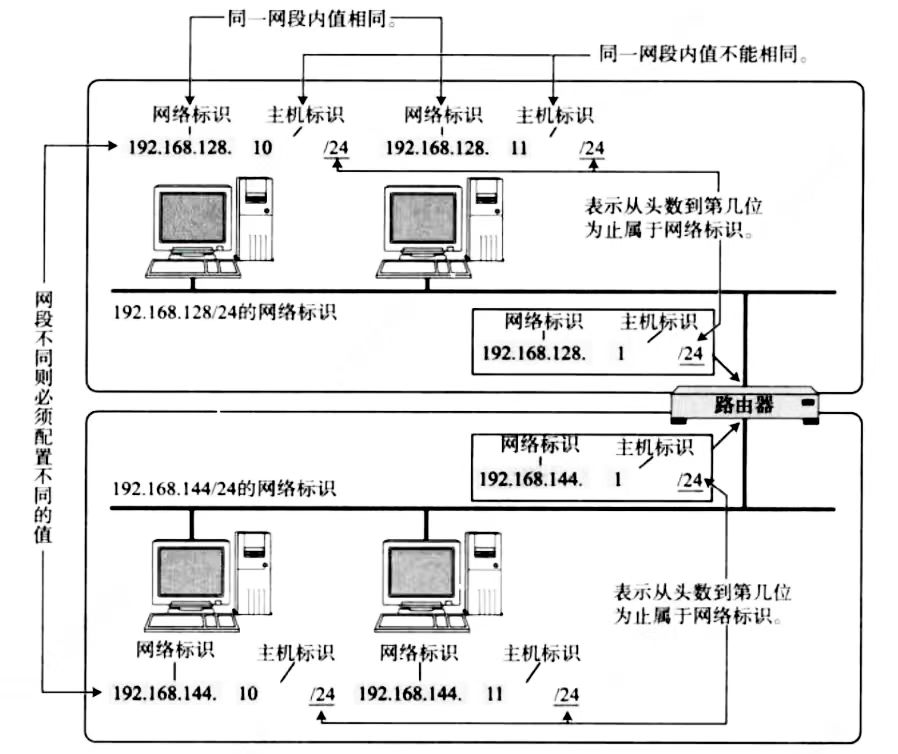
每一个路由器下就是一个子网,一个子网中的每个主机的网络号是相同的,主机号必须不同。每次有新主机加入子网,路由器都会自动分配一个主机号给这个主机,关于路由器是如何自动分配的,具体的技术叫做DHCP,能够自动的给子网内新增的主机节点分配IP地址,避免手动管理。那么路由器也可以看作一个DHCP服务器
IP地址分类
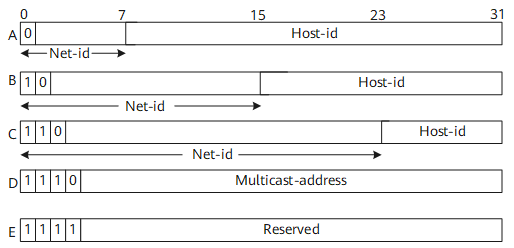
| 网络类型 | 地址范围 | 说明 |
|---|---|---|
| A | 0.0.0.0~127.255.255.255 | 全0的主机号码表示该IP地址就是网络的地址,用于网络路由;全1的主机号码表示广播地址,即对该网络上所有的主机进行广播。 |
| B | 128.0.0.0~191.255.255.255 | 全0的主机号码表示该IP地址就是网络的地址,用于网络路由;全1的主机号码表示广播地址,即对该网络上所有的主机进行广播。 |
| C | 192.0.0.0~223.255.255.255 | 全0的主机号码表示该IP地址就是网络的地址,用于网络路由;全1的主机号码表示广播地址,即对该网络上所有的主机进行广播。 |
| D | 224.0.0.0~239.255.255.255 | D类地址是一种组播地址。 |
| E | 240.0.0.0~255.255.255.255 | 保留。255.255.255.255用于局域网广播地址。 |
随着internet的发展,这种划分方案的局限性就显现出来了,大多数组织都申请B类网络地址,导致B类地址很快都分完了(B类地址的一个网段下允许六万五千多个主机),并且A类却浪费了大量地址(A类地址的一个网段下允许更多个主机)。但是实际网络架设中,并不会出现一个子网中存在这么多主机的情况,大多数IP地址都被浪费掉了
所以针对这种情况提出了一个新划分方案:CIDRClassless Interdomain Routing(无类别区间路由)
- 引入一个额外的子网掩码
subnet mask来区分网络号和主机号 - 子网掩码也是一个32位的正整数,通常是一串0结尾
- 将子网掩码与IP地址按位与操作,得到的结果就是网络号
- 所以网络号和主机号的划分与这个IP地址是A、B、C类无关

所以,IP地址与子网掩码之前做按位与运算可以得到网络号,此外的位中从全0到全1就是主机号
IP地址和子网掩码还有一种更简洁的表示方法,例如140.252.20.68/24,表示IP地址为140.252.20.68,子网掩码的高24为是1,也就是255.255.255.0
一些特殊的IP地址
将IP地址中的主机地址全部设为0,就成为了网络号,表示这个子网
将IP地址中的主机地址全部设为1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包
127.*的IP地址用于本机环回loop back测试,通常就是127.0.0.1
IP地址的数量限制
IP地址是一个32位的正整数,最多表示的数是2^32也就是42亿多,TCP/IP协议规定每一个主机都需要有一个IP地址,但是世界上的主机数量可远不止这个数,并且还要除去一些特殊的IP地址,难道能接入网络的主机连42亿都不到吗?肯定不是这样的
CIDRClassless Interdomain Routing(无类别区间路由)在一定程度上缓解了这个问题,提高利用率,减少浪费,但IP地址的绝对上限并没有增加,
- 动态分配IP地址:只对接入网络的设备分配IP地址,所以同一个MAC地址的设备每次接入互联网中得到的IP地址不一定相同
- NAT
Network Address Translation(网络地址转换)👇 - IPv6:首先IPv6不兼容IPv4,它们是不同的两个协议;IPv6使用128个位(16字节)来表示一个IP地址
2^128 = 3.4028237 * 10^38;IPv6现在并不普及
私有IP和公网IP
如果一个组织内部组建局域网,IP地址只用于局域网内的通信,而不直接连到Internet上,理论上使用任意的IP地址都可以,但是RFC 1918规定了用于组建局域网的私有IP地址
10.*,前8位是网络号,一共16,777,216个地址172.16.*到172.31.*,前12位是网络号,共1,048,576个地址192.168.*,前16位是网络号,共65,536个地址
包含在这个范围内的都成为私有IP,其余的称为全局IP或者公网IP
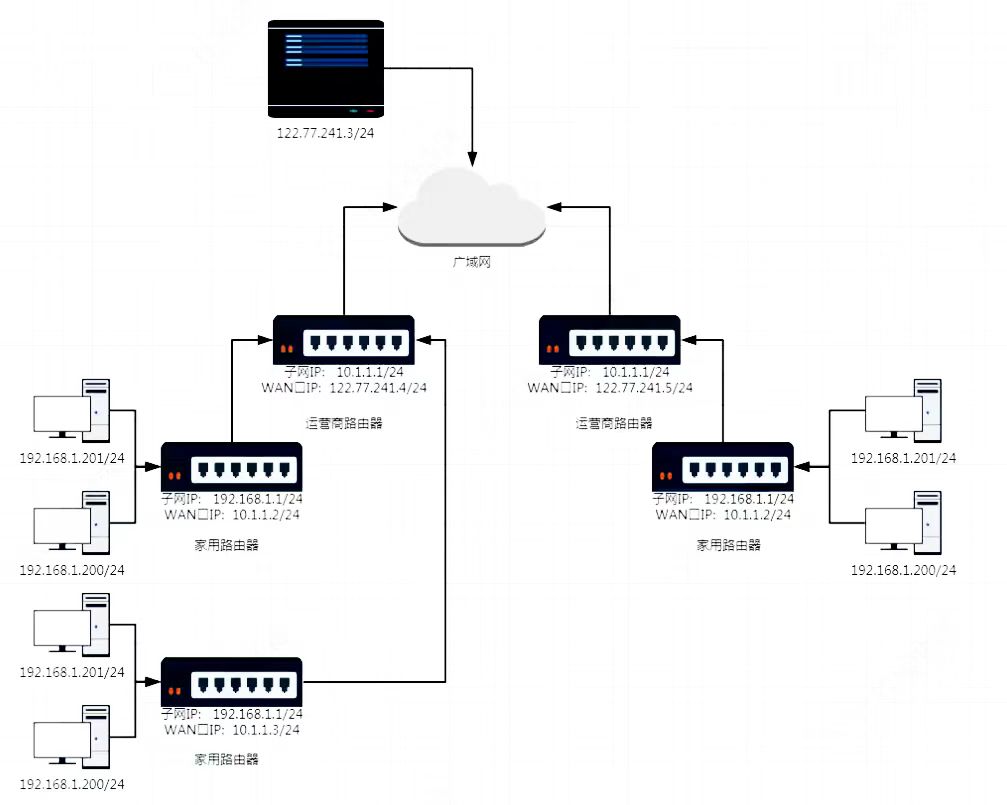
- 一个路由器可以配置两个IP地址,WAN口IP,LAN口IP(子网IP)
- 路由器LAN口连接的主机,都从属于当前这个路由器的子网中
- 不同的路由器,子网IP其实都是一样的通常都是
192.168.1.1。子网内的主机IP地址不能重复,但是不同子网间的IP地址可以重复 - 每一个家用路由器,其实有作为运营商路由器子网中的一个节点,这样运营商路由器可能会有很多级,最外层的运营商路由器的WAN口IP就是一公网IP了
- 子网内的主机需要和外网进行通信时,路由器将IP首部中的IP地址进行替换(替换成当前子网中路由器的WAN口IP),这样逐级替换,最终数据包中的IP地址会成为一个公网IP,这种技术称为 NAT
Network Address Translation(网络地址转换) - 如果希望我们自己实现的服务器程序,能够在公网上被找到,就需要把服务部署在一个有公网IP的主机上,也就是我们在阿里云 or 腾讯云上面购买的服务器
什么是公网什么是私网
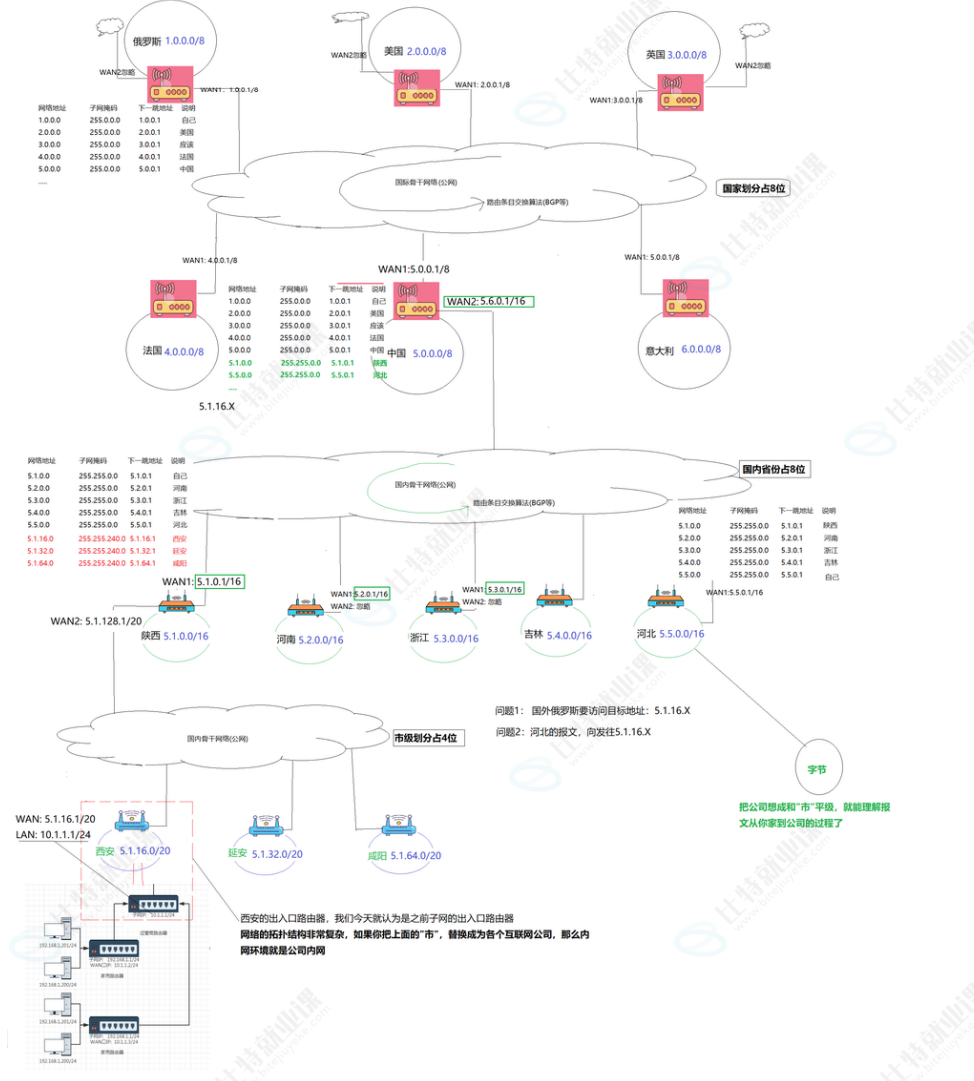
真实的网络结构非常复杂,即涉及到划分公网IP的组织,ICANN,还要在全球范围内进行区域划分, 比如亚太,北美,欧洲等,又要考虑各个国家内部的ISP代理,整体拓扑非常复杂,我们简化所有过程,简单理解公网即可
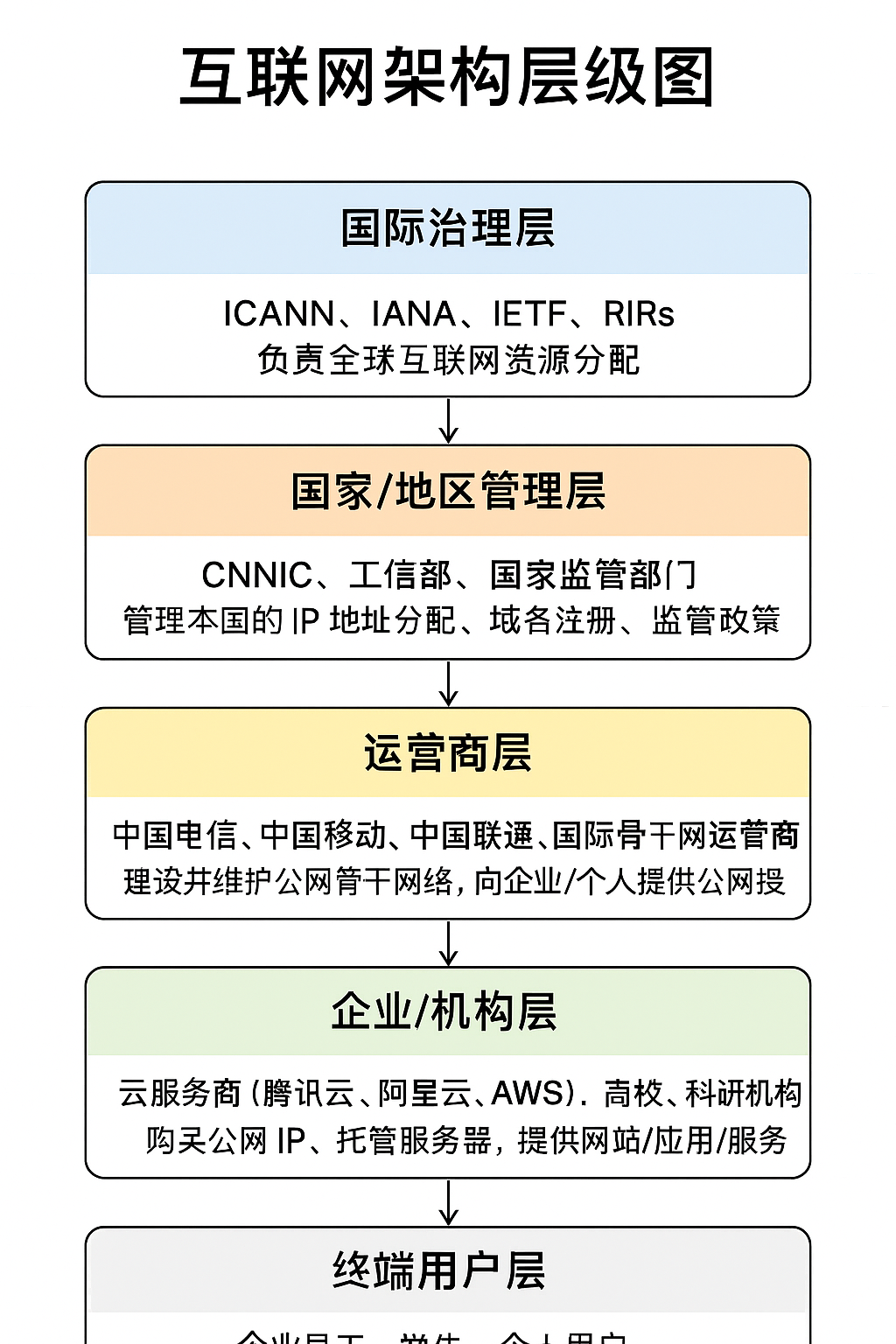
附录有关于建设公网的参与者,和职责说明,AI提示词:公网的整个构建过程,需要涉及到谁,各自核心角色和作用是什么?
非常棒的问题,这其实触及了互联网的“骨架结构”🌐。
我们可以把“公网的构建过程”理解为:从一个全球互联的网络(Internet)是如何被建起来、运营、分配、接入、使用的?
下面我会分层讲解:
从 国际 → 国家/地区 → 运营商 → 企业/个人
每一层是谁、做什么、为什么重要。
🧱 一、互联网的全局架构层次(谁参与)
层级 代表机构/角色 核心职责 🌍 国际治理层 ICANN、IANA、IETF、RIRs(如 APNIC、ARIN) 负责全球互联网资源分配(IP 地址、域名根服务器、标准协议) 🇨🇳 国家/地区管理层 国家互联网信息中心(CNNIC)、工信部、国家监管部门 管理本国的 IP 地址分配、域名注册、监管政策 🏢 运营商层(ISP) 中国电信、中国移动、中国联通、国际骨干网运营商 建设并维护公网骨干网络,向企业/个人提供公网接入 🏫 企业/机构层 云服务商(腾讯云、阿里云、AWS)、高校、科研机构 购买公网 IP,托管服务器,提供网站/应用/服务 👨💻 终端用户层 企业员工、学生、个人用户 通过 ISP 或 VPN 接入公网,访问和发布信息
🧩 二、公网构建的核心组成部分
1️⃣ 地址体系(IP 地址)
- 谁分配:
- 顶层由 IANA 分配 IP 段给五大 RIR(区域互联网注册机构)。
- 比如亚洲的就是 APNIC。
- 中国由 CNNIC 从 APNIC 拿资源再分配给各大运营商或机构。
- 作用:保证全球每个公网地址唯一不冲突。
🧠 举例:
腾讯云申请公网 IPv4 → CNNIC → APNIC → IANA
是一条逐级授权链。
2️⃣ 域名系统(DNS)
- 谁参与:
- ICANN 管理根域(.com、.net 等)。
- 域名注册商(如阿里云、新网)负责分配二级域名。
- 作用:
- 将易读的名字(
www.example.com)解析为 IP 地址。- 关键基础设施:
- 全球 13 组 根域名服务器。
- 各国的顶级域名(.cn、.jp、.uk)由本地注册局管理。
3️⃣ 传输骨干(物理网络)
- 谁建的:
- 国家级骨干网:ChinaNet(电信)、CNCNet(联通)、CMNet(移动)。
- 国际出口:跨国光缆、卫星链路。
- 作用:
- 构建互联网“高速公路”,承载所有数据传输。
- 关键技术:
- BGP(边界网关协议)——让不同自治系统互联。
- OSPF/MPLS 等——控制内部路由。
4️⃣ 公网接入服务
- 谁提供:
- 电信/联通/移动、以及云服务商。
- 作用:
- 给企业或个人分配公网 IP 或 NAT 出口。
- 提供宽带、5G、IDC、VPN、CDN 等接入方式。
- 关键点:
- 公网 IP 是稀缺资源(特别是 IPv4)。
- IPv6 正在快速替代。
5️⃣ 内容与服务层
- 谁运营:
- 各类互联网公司(百度、腾讯、Google、YouTube……)。
- 作用:
- 运行网站、APP、API 服务。
- 核心机制:
- CDN 加速、DNS 负载均衡、HTTPS 安全通信。
⚙️ 三、构建公网的关键环节(按顺序)
步骤 内容 主要参与者 1️⃣ 获得全球唯一的 IP 地址段 IANA → RIR → ISP 2️⃣ 建设国际与国内骨干网 运营商、政府机构 3️⃣ 设置自治系统(AS)并建立 BGP 路由 ISP、数据中心 4️⃣ 部署 DNS 体系 ICANN、注册局、云服务商 5️⃣ 向用户分配公网接入 运营商 6️⃣ 用户搭建服务并上线 企业、个人、云平台 7️⃣ 国家层面监管与安全审查 政府监管机构(工信部、网信办)
🧭 四、关系拓扑简图(文字版)
2
3
4
5
6
7
8
9
10
11
↓
[ RIR/APNIC ]
↓
[ CNNIC/工信部 ]
↓
[ ISP (电信/移动/联通) ]
↓
[ 云平台 / 企业网络 ]
↓
[ 终端用户 ]
💡 五、总结一句话
公网是一个由 国际组织分配规则、国家机构监管分配资源、运营商建设骨干、企业与个人接入使用 的多层协作体系。
每个节点都保证了“全球唯一、可达、安全、规范”这四个特性。
把这个内容画成一张「互联网架构层级图(带机构与作用)」的视觉图
这样一眼就能看到每个角色之间的关系。
路由
在复杂的网络结构中,找出一条通往终点的路线
唐僧西天取经,到了黄风岭,唐僧只知道他的最终目标是天竺灵山,但是他到了黄风岭后不知道下一站要去哪,就只能向当地人问。这和路由的过程相似
路由的过程,就是这样一跳一跳(Hop by Hop) “问路”的过程。所谓“一跳”就是数据链路层中的一个区间。具体在以太网中指从源MAC地址到目的MAC地址之间的帧传输区间
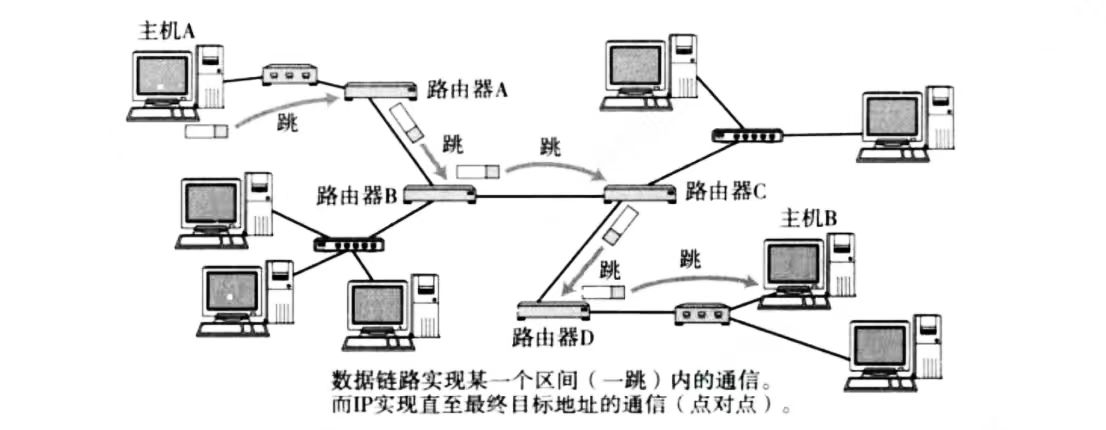
IP数据包的传输过程也和问路一样
- 当IP数据包,到达路由器时,路由器会先查看目的IP
- 路由器决定这个数据包是能直接发送给目标主机,还是需要发送给下一个路由器
- 依次反复,一直到达目标IP地址;
那么如何判定当前这个数据包该发送到哪里呢?这个就依靠每个节点内部维护一个路由表
Windows下使用route PRINT查看路由表
1 | C:\Users\wq>route PRINT |
🧭 一、核心逻辑:根据路由表查找下一跳(Next Hop)
当一个 IP 数据包到达路由器时,路由器主要做 3 件事:
1️⃣ 读取包头中的目标 IP 地址(Destination IP)
2️⃣ 在本地路由表中查找匹配项
3️⃣ 根据最佳匹配结果,转发到对应的“下一跳”接口
📘 二、什么是路由表(Routing Table)
路由表是路由器或主机内部维护的一张“方向地图”,
每一条路由表项告诉设备:
字段 含义 目标网络 (Destination) 要去的 IP 网段,比如 192.168.1.0/24子网掩码 (Netmask) 用于匹配目标 IP 属于哪个网络 下一跳 (Next Hop / Gateway) 应该把包发给哪个下一个路由器 出接口 (Interface) 使用哪块网卡发出去 跃点数/度量值 (Metric) 多条路径时选择最优的一条(越小越优)
📋 举例:某路由器的路由表
目标网段 子网掩码 下一跳 出接口 说明 192.168.1.0 255.255.255.0 — eth0 直连网段 10.0.0.0 255.255.0.0 192.168.1.254 eth0 通过网关转发 0.0.0.0 0.0.0.0 192.168.1.1 eth0 默认路由(通往互联网)
🔍 三、匹配规则:最长前缀匹配(Longest Prefix Match)
当目标 IP 与多条路由表都能匹配时,
路由器会选择 “网络位最长(掩码最多的)那一条”。举个例子:
目标 IP 路由表项 匹配掩码位数 结果 192.168.1.25 192.168.0.0/16 16 ✅ 192.168.1.25 192.168.1.0/24 24 ✅✅ → 选它 👉 所以会选择
/24那条,因为匹配更具体。
⚙️ 四、路由来源类型
类型 来源 说明 直连路由 接口配置 IP 时自动生成 最优、最直接 静态路由 管理员手动配置 简单稳定、但需人工维护 动态路由 路由协议自动学习(如 OSPF/BGP) 可自适应网络变化
*路由表生成算法
🌐 一、路由表的来源总览
路由表可以由三种方式生成:
来源 说明 示例 直连路由(Direct Route) 当接口配置 IP 时自动加入路由表 比如: eth0配置为 192.168.1.1/24 → 自动生成192.168.1.0/24静态路由(Static Route) 管理员手动设置固定的路径 ip route add 10.0.0.0/16 via 192.168.1.254动态路由(Dynamic Route) 路由协议(如 RIP、OSPF、BGP)自动计算 网络大规模时必须依赖它
🧩 二、静态路由算法(最简单的生成方式)
静态路由 没有算法推算,而是由管理员手动配置:
此时系统直接写入路由表:
2
3
4
Next Hop: 192.168.1.1
Interface: eth0
Metric: 1优点:简单、稳定、不易波动
缺点:拓扑变化时无法自动更新
⚙️ 三、动态路由算法分类总览
动态路由的核心在于「路由表的自动计算算法」,主要有三类👇
类型 常见协议 基本思想 适用范围 距离向量算法(Distance Vector) RIP、BGP(部分) 每个路由器周期性广播“我到各网段的距离”,邻居更新后继续传播 小规模网络,结构简单 链路状态算法(Link State) OSPF、IS-IS 每个路由器向全网广播自己的链路信息,所有路由器都计算全网最短路径 中大型网络 路径向量算法(Path Vector) BGP(核心算法) 每个路径携带完整的“经过的自治系统序列”,避免环路 跨自治系统(AS)互联
🔢 四、主要算法原理详解
1️⃣ 距离向量算法(Distance Vector)
代表协议:RIP (Routing Information Protocol)
核心思想:
每个路由器维护一张表,表里记录“到每个网络的距离(跳数)”。
每隔一段时间向邻居广播这张表,邻居再更新自己的表。关键算法:Bellman-Ford
公式:
其中:
D(X, Y):X 到 Y 的最短距离cost(X, N):X 到邻居 N 的代价D(N, Y):邻居 N 到目标 Y 的距离特点:
- 简单易实现
- 收敛慢、可能出现路由环路
- 有 “水平分割”(Split Horizon)等防环机制
2️⃣ 链路状态算法(Link State)
代表协议:OSPF (Open Shortest Path First)
核心思想:
- 每个路由器检测与邻居的链路状态(带宽、延迟等);
- 把这些信息组成链路状态通告(LSA);
- 使用泛洪(Flooding)向全网广播;
- 每个路由器得到完整拓扑后,用 Dijkstra 最短路径算法(SPF) 计算最佳路径;
- 将结果写入路由表。
算法关键:Dijkstra(最短路径优先)
步骤简化:
2
3
4
2. 找出从 S 出发,代价最小的节点 v
3. 更新所有相邻节点的最短路径
4. 重复直到所有节点都确定特点:
- 全网拓扑同步,路径最优;
- 收敛快;
- 内存开销大,计算复杂度高。
3️⃣ 路径向量算法(Path Vector)
代表协议:BGP(互联网核心协议)
核心思想:
- 每个自治系统(AS)告诉邻居自己可以到达哪些前缀;
- 同时附上“路径向量”——经过的 AS 列表;
- 其他 AS 根据策略选择最合适的路径;
- 若发现路径中包含自己,则丢弃(防止环路)。
算法特征:
- 不计算代价,而是基于 策略(Policy);
- 是互联网骨干(AS 间)互联的基础。
🧠 五、最终:路由表的生成流程(动态情况)
2
3
4
5
6
7
8
9
10
11
↓
收到邻居路由更新(RIP/OSPF/BGP)
↓
执行对应算法(Bellman-Ford / Dijkstra / Path Vector)
↓
生成候选路径集
↓
根据优先级(管理距离、Metric)选最佳
↓
写入本地路由表
💡 六、小结对比
算法类型 核心思想 优点 缺点 距离向量(RIP) 邻居间交换“距离” 简单 收敛慢、有环风险 链路状态(OSPF) 全网拓扑+Dijkstra 路径最优、收敛快 资源开销大 路径向量(BGP) AS 级路径传播 可控、策略灵活 配置复杂
数据链路层
和网络层对比
网络层协议用于不同子网之间的通信;数据链路层协议则是用于在同一子网下的设备通信如:主机与主机之间,主机与路由器之间
以太网帧格式
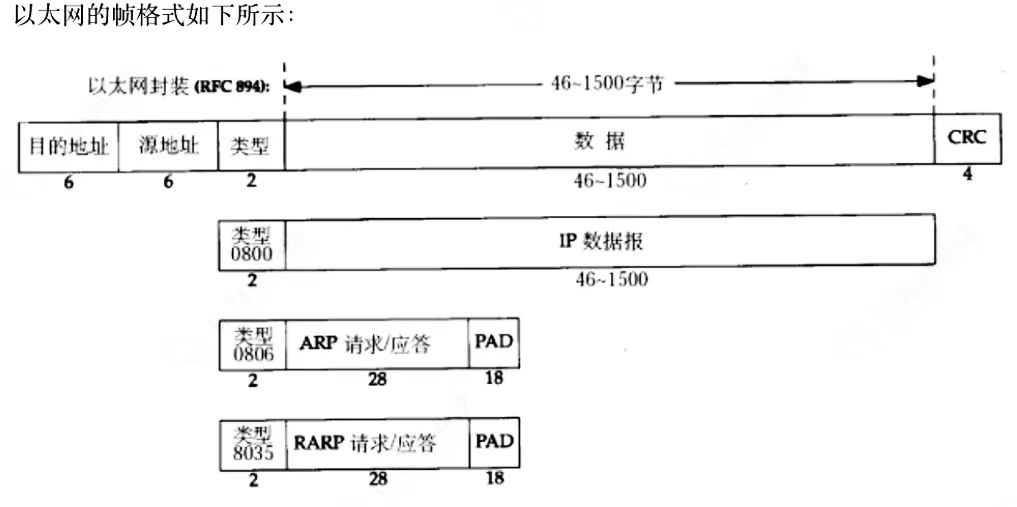
- 原地址和目的地址就是指网卡的硬件地址(MAC地址)长度48位,是在网卡出厂时就被固化了的
- 帧格式类型字段有三种值,IP、ARP、RARP
- 帧末尾是CRC校验码
MAC地址
- MAC地址是用来识别在同一子网下不同的主机节点的
- 长度48位,6字节;一般用16进制数字加上冒号来表示,例:
08:00:27:03:fb:19 - MAC地址是在网卡出厂时就确定了,不能修改,MAC地址通常是唯一的(虚拟机中的MAC地址不是真实的MAC地址,可能冲突,有些网卡也支持用户自己配置MAC地址)
- 在网络传输中,MAC地址标识的是在这个子网中我需要去哪里,是路途上的每一个区间的起点和终点;IP地址标识的是我最终需要去哪,是路途总体的起点和终点
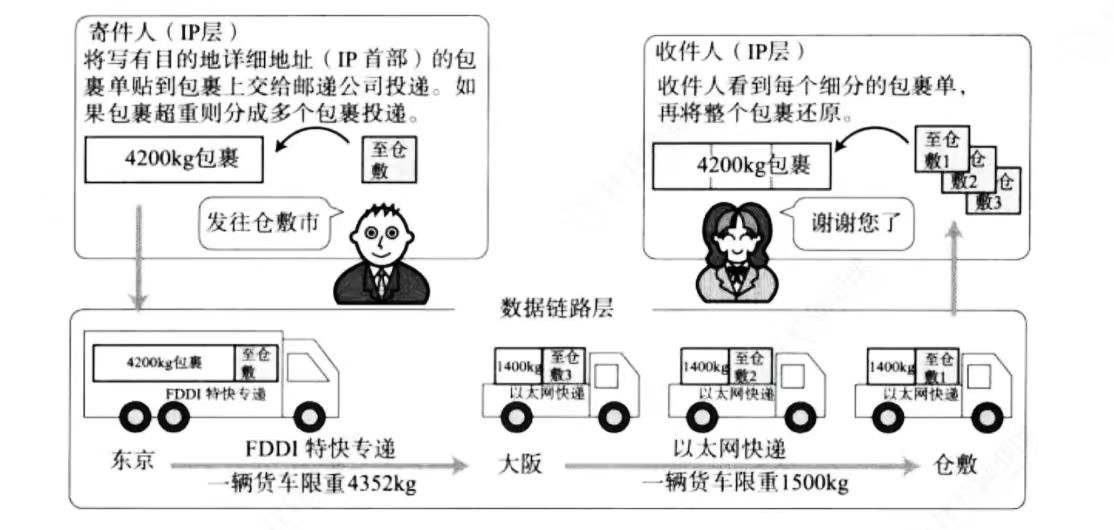
MTU
MTU相当于发快递时对包裹尺寸的限制,这个限制不同于数据链路层对应的物理层产生的限制- 以太网帧中的数据长度规定最小为46字节,最大1500字节,
ARP数据包的长度不够46字节,需要在后面补填充位 - 最大值1500称为以太网的最大传输单元
MTU不同的网络有不同的MTU - 如果一个数据包从以太网路由到拨号链路上,数据包长度大于拨号链路的
MTU了,则需要对数据包进行分片fragmentation - 不同的数据链路层标准的
MTU是不一样的
MTU和IP协议
因为有MTU,所以对于较大的IP数据包(超过1500字节)要进行分片处理
- 将较大的IP包分成多个小包,并给每一个小包打上标签
id(IP协议头的16位标识),由同一个大数据包切分成的每一个小数据包中的id字段都是相同的 - 每一个小包的IP协议头的三位标志字段中,第2位置为0,表示允许分片,第三位来表示结束标记(也就是当前是否为最后一个小包,是为1,否则置为0)
- 当这些小包到达对端时,会按IP报头中分片偏移字段的值进行顺序重组,拼装到一起返回给传输层;并且一旦这些小包中的任意一个小包丢失,接收端的重组就会失败,但IP层是不会负责重新传输数据的(这个能力是由传输层的TCP协议负责)
所以网络层和数据链路层是让主机拥有端到端传输数据的能力,但是传输的鲁棒性,稳定,可靠,这就是传输层协议TCP管的事,这就是为什么叫做TCP传输控制协议
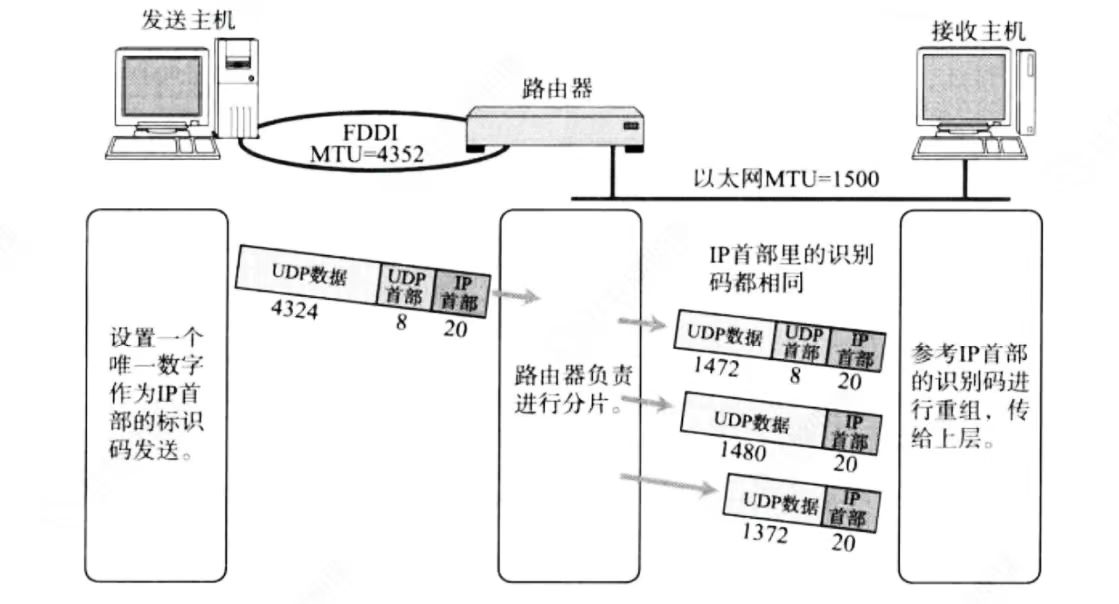
MTU和UDP协议
一旦UDP携带的数据超过1472(1500 - 20(IP首部) - 8(UDP首部)),那么就会在网络层分成多个IP数据报,这个数据报有任意一个丢失,都会引起接受端网络重组失败。这就意味着,如果UDP数据报在网络层被分片,整个数据被丢失的概率就大大增加了
MTU和TCP协议
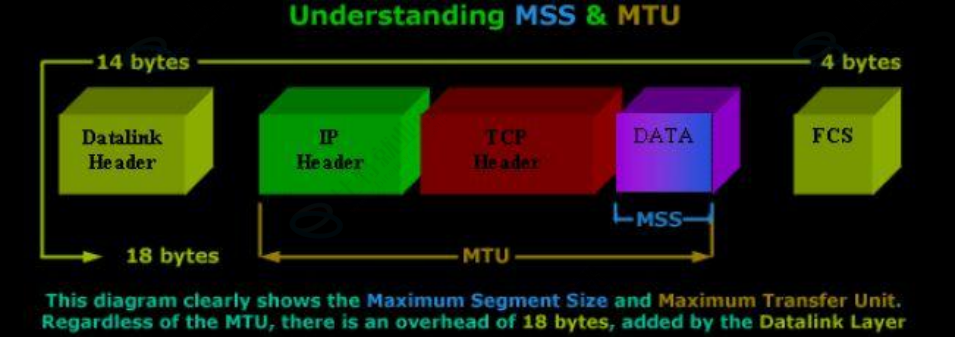
- TCP协议的一个数据报也是不能无限大的,同样受制于MTU,TCP的单个数据报的最大消息长度称为MSS
Max Segment Size - TCP在建立连接的过程中通信双方会进行MSS协商,理想情况下MSS的值正好就是IP在不会分片处理的最大长度(这个长度仍然受制于数据链路层的MTU)
- 双方在发送SYN的时候会在TCP头部写入自己能支持的MSS值,之后双方知道对方的MSS值之后,选择较小的作为最终MSS
- 最后MSS的值就是在TCP首部40字节的变长选项中
使用ifconfig命令,即可查看IP地址,MAC地址,和MTU
1 | wq@wq-VMware-Virtual-Platform:~$ ifconfig |
ARP协议
注意:ARP协议不是一个单纯的数据链路层的协议,而是一个介于数据链路层和网络层之间的协议
ARP协议的存在是为了建立主机IP地址和MAC地址之间的映射关系
- 在网络通信时,源主机的应用程序知道目的主机的IP地址和端口号,却是不知道目的主机的硬件地址
- 数据包先是被网卡接收到再去处理上层协议的,如果接受到的数据包的硬件地址与本机不相符,则直接丢弃
- 因此在通信之前必须获得目标主机的硬件地址
🧩 一、ARP 的作用
ARP 协议位于 网络层与链路层之间,其核心任务是:
根据 IP 地址,解析出对应主机的 MAC 地址。
因为:
- IP 地址是逻辑地址,用于网络层路由;
- 但实际通信(例如在以太网中)是通过 MAC 地址 进行的;
- 所以,当主机要向同一局域网内的某个 IP 地址发送数据时,必须先通过 ARP 协议 找出它的 MAC 地址。
⚙️ 二、ARP 工作流程概览
ARP 的整个过程分为 查询 和 响应 两步:
1️⃣ 发送 ARP 请求(ARP Request)
当主机 A 想向主机 B 发送数据,但不知道 B 的 MAC 地址时,会:
- 在自己的 ARP 缓存表中查找目标 IP 对应的 MAC 地址;
- 如果找不到,就广播发送一条 ARP 请求报文:
- 发送方 MAC:A 的 MAC;
- 发送方 IP:A 的 IP;
- 目标 MAC:
00:00:00:00:00:00(未知);- 目标 IP:B 的 IP;
- 报文类型:广播(
FF:FF:FF:FF:FF:FF)。📡 所有主机都会收到这条广播。
2️⃣ 接收 ARP 响应(ARP Reply)
主机 B 收到 ARP 请求后会检查:
- 如果目标 IP 与自己 IP 相同,就说明请求是给自己的;
- B 就会单播(unicast)一个 ARP 响应报文 给 A:
- 发送方 MAC:B 的 MAC;
- 发送方 IP:B 的 IP;
- 目标 MAC:A 的 MAC;
- 目标 IP:A 的 IP。
A 收到后:
- 把「B 的 IP ↔ B 的 MAC」映射关系写入 ARP 缓存表;
- 之后发往 B 的数据帧就可以直接用这个 MAC 地址进行通信。
🧠 三、ARP 缓存表(ARP Cache)
每台主机会维护一个 ARP 表(缓存),记录 IP 与 MAC 的映射:
2
3
192.168.1.2 00-1A-2B-3C-4D-5E 20分钟
192.168.1.3 00-1C-42-AA-BB-CC 20分钟特点:
- 命中表项时无需再广播请求;
- 超时后表项会被删除(通常几十秒到几分钟)。
查看命令:
- Windows:
arp -a- Linux/macOS:
ip neigh show或arp -n
📦 四、ARP 报文结构(以太网示例)
注意到源MAC地址、目的MAC地址在以太网首部和ARP请求中各出现一次,对于链路层为以太网的情况是多余的。但如果链路层是其它类型的网络则有可能是必要的
字段 说明 硬件类型 1(以太网) 协议类型 0x0800(IPv4) 硬件地址长度 6 协议地址长度 4 操作码 1=请求,2=响应 发送端 MAC 地址 源 MAC 发送端 IP 地址 源 IP 目标端 MAC 地址 目标 MAC(请求时为空) 目标端 IP 地址 目标 IP
🌐 五、完整示例(主机 A 想找主机 B)
假设:
2
B: 192.168.1.20, MAC B0-B1-B2-B3-B4-B5流程:
1️⃣ A 想发数据给 B → 查 ARP 表,未命中
2️⃣ A 广播发送 ARP 请求:
3️⃣ B 收到后发现目标 IP 是自己 → 回复单播:
4️⃣ A 收到响应 → 更新 ARP 表:
5️⃣ 之后 A 可以直接通过该 MAC 发送以太帧。
⚠️ 六、安全与特性
- ARP 是无认证机制的,因此容易受到:
- 🔥 ARP 欺骗(ARP Spoofing)
- 🔥 中间人攻击(MITM)
- 为防御,可使用:
- 静态 ARP 表;
- 动态检测与防护工具(如
arpwatch、交换机安全端口绑定)。
🧭 七、总结流程图
2
3
4
5
6
7
8
9
10
11
12
13
14
15
│ A要发数据 │
└────┬───────┘
│ 查ARP表
▼
命中?───►是──►直接发数据
│否
▼
发送ARP请求广播
│
▼
B收到并回应ARP应答
│
▼
A更新ARP表并开始通信

为什么要有 ARP 缓存表?
🎯 原因:避免频繁广播,提升效率
如果每次通信都要重新广播 ARP 请求:
- 整个局域网都会收到广播;
- 每台主机都要处理;
- 延迟增加、网络负载变大。
所以操作系统会维护一个 ARP 缓存表(ARP Cache Table),
记录最近解析过的 IP–MAC 映射关系:
IP地址 MAC地址 状态 过期时间 192.168.1.2 00-1A-2B-3C-4D-5E 动态 20 min 192.168.1.3 00-1C-42-AA-BB-CC 动态 20 min 📦 当下次再给同一台主机发数据时,直接查表即可,不必广播。
✅ 优点:
- 极大减少广播包;
- 提高网络效率;
- 降低CPU处理负担。
为什么 ARP 表项要有过期时间?
如果 ARP 表项 永久有效,会产生严重问题👇
⚠️ 1. MAC 地址可能会变
- 局域网内主机的 网卡可能更换;
- 或主机 重启后 DHCP 分配了新 IP;
- 又或目标设备 下线,被另一台设备复用 IP 地址。
此时,旧的 IP–MAC 对应关系已经 不再正确。
如果缓存表不更新,主机会:
- 把数据发到错误的 MAC;
- 造成通信失败或数据错发。
所以要定期清理、重新学习。
⚠️ 2. 防止 ARP 欺骗攻击持续生效
如果攻击者伪造 ARP 响应,把网关 IP 指向自己的 MAC,
那受害主机的 ARP 表项会被污染。➡️ 有过期时间就意味着:
- 一段时间后会自动失效;
- 系统会重新广播请求,可能恢复正确映射。
这是对 ARP 欺骗 的一种「被动恢复」机制。
⚙️ 3. 保证网络拓扑动态变化时仍可通信
在动态网络(例如虚拟机迁移、移动设备切换接入点)中,
MAC 地址与 IP 的绑定经常变化。👉 定期更新 ARP 表可确保数据包走向最新的目标设备。
📐 三、缓存时间是如何设定的?
各系统有不同默认值:
系统 动态表项有效期 Windows 2 分钟(活动时可延长至 10 分钟) Linux 通常 60 秒到 20 分钟不等 Cisco 路由器 4 小时(可配置) 静态表项(
arp -s添加的)则不会过期,但:
- 需管理员手动配置;
- 适合固定设备(如网关、服务器);
- 不适合移动或经常变动的网络环境。
🧩 四、总结类比
设计目标 原理类比 ARP 缓存表 像「通讯录」——查过一次就记下来,下次不用再问 表项过期 像「定期刷新通讯录」——防止号码变了还打旧的 永不过期的风险 信息可能过时 → 通信失败或被欺骗
✅ 总结一句话
ARP 缓存表 是为减少广播与延迟而存在的,
过期时间 是为保证网络映射动态更新、防止错误和攻击而设置的。